


Terminy takie jak „big data”, „data mining” czy „sztuczna inteligencja” pojawiają się w mediach coraz częściej. Jeszcze kilka lat temu, gałęzie nauki (informatyki) z tym związane były w dużej mierze tworami teoretycznymi i akademickimi lub znajdywały zastosowania w rozwiązaniach dla wielkich korporacji, które musiały radzić sobie z przetwarzaniem ogromnej ilości danych.
Słowo dane będzie kluczowe w całym tym tekście. Jedna z ciekawszych i prostszych definicji, mówi, że dane to wszystko co jest/może być przetwarzane umysłowo lub komputerowo. Te same dane mogą mieć wiele poziomów, na których są one analizowane. W przypadku komputerów i maszyn liczących – bo na tym się skupimy – najniższą warstwą danych jest ich zapis binarny. W niższych stopniach abstrakcji, „tłumaczone” są one na liczby dziesiętne, słowa, obrazy bitmapowe (rastrowe), itd. Na jeszcze wyższym poziomie, dane mogą być bardziej specyficzne i kategoryzowane – ciągi słów i liczb mogą oznaczać kolory, adresy, modele samochodów, dane biometryczne czy nawet całe profile psychologiczne.
Poprzednie dziesięciolecie, dzięki szybkiemu rozwojowi Internetu, to boom na dane. Były one najważniejsze i spływały z wielu źródeł. Dane meteorologiczne, dane o stanie zdrowia, dane gospodarcze, dane o użytkownikach sieci, dane o ruchu w sieci czy jakiekolwiek inne dane statystyczne, do których nigdy nie mieliśmy dostępu tak szybko i w tak wielkiej skali. Niesamowite źródło do późniejszych analiz. Problem jednak tkwił w tym, że dane to niekoniecznie informacje, a tym bardziej nie wiedza. Jak to rozumieć? Odbiorcy zostali zalani ogromem zer i jedynek, które zawierały dane. Dane różnego typu. Same w sobie, często nie miały one w sobie jednak żadnej wartości. Po co komu dane ze wszystkich stacji meteorologicznych na świecie, jeśli nie potrafimy na ich podstawie prognozować pogody? Co nam z danych o umieralności i zachorowalności w Indiach, skoro nie potrafimy znaleźć tam żadnej korelacji, ani zależności przyczyna-skutek?


Czasami dane są wartością samą w sobie (np. możemy sprzedać dane o użytkownikach – ich adresy email czy numery telefonów). Szczególnie na początku – obecnie ich wartość sukcesywnie spada. Największej wartości nabierają one jednak wtedy, gdy potrafimy na ich podstawie wnioskować, prognozować, grupować czy wyciągać wnioski. W skrócie – na podstawie danych możemy uzyskiwać WIEDZĘ na temat jakiegoś zjawiska. Z jednolitego szumu gigantycznej ilości danych dostajemy ROZUMIENIE dzięki WNIOSKOWANIU. Doszliśmy do pierwszego etapu – przetwarzanie danych. Algorytmy ich przetwarzania mogą być bardzo złożone, ale z początku można je było nazwać „prostymi” dlatego, że ich twórcy pisali je w określonym celu.
Wiedzieli czego algorytm ma szukać. Na przykład w bezpłciowym zbiorze transakcji klientów i ich danych mieli odnaleźć zależności – które grupy wiekowe, kupują które grupy produktów. Ile wydają średnio pieniędzy. Czy koszyk zakupowy kobiety i mężczyzny różni się. Jakkolwiek skomplikowane byłyby algorytmy klasyfikacji za tym stojące, sama idea jest prosta – szukamy określonych, zaprogramowanych przez człowieka zależności na zamkniętym zbiorze danych. Klasyczny „data mining”, czyli jeden z elementów procesu odkrywania wiedzy z relacyjnych baz danych. Idea data miningu polega na wykorzystaniu maszyn do znajdowania nietrywialnych prawidłowości w danych zgromadzonych w hurtowniach danych („data warehouses”).
Podejście to jednak wiąże się z wieloma problemami, szczególnie w świecie, gdzie danych jest coraz więcej (brak zamkniętych zbiorów), są one niejednorodne i trudne do przetwarzania maszynowego. Jesteśmy obecnie tak przeładowani danymi (mówiąc my, mam szczególnie na myśli wielkie korporacje, które te dane gromadzą i przetwarzają), że nie zawsze wiemy czego w nich szukać. Niektóre zależności między nimi nie są oczywiste. Czasami dane są niespójne lub wybrakowane. Dane z GPS, wyszukiwanych fraz, odwiedzanych stron, opasek fitness, częstotliwości wysyłania smsów, czy nawet treści naszych e-maili. Ale również najróżniejszych danych medycznych czy meteorologicznych, których nie sposób nam przekopać ręcznie. Ba, nie wiemy nawet czego szukać i chcielibyśmy, żeby maszyna nie tylko znalazła szukaną przez nas zależność czy prawidłowość. Chcemy, żeby maszyny same definiowały nowe kryteria wyszukiwania i odkrywały ukryte korelacje czy relacje. Chcemy, żeby z każdą kolejną porcją danych maszyna stawała się „mądrzejsza”, a jej algorytmy doskonalsze. Chcemy, żeby to maszyna powiedziała nam co wynika z danych, bez konieczności formułowania problemu a priori. Bez konieczności ręcznego uczenia jej. To dane mają ją uczyć, a nie człowiek. I właśnie w tym momencie dochodzimy do wspomnianego w tytule uczenia maszynowego.
Uczenie maszynowe
Uczenie maszynowe (machine learning), to dziedzina nauki zajmująca się tworzeniem algorytmów, które mogą „uczyć” się na podstawie przetwarzanego przez siebie zbioru danych. Takie algorytmy funkcjonują w oparciu o dynamiczne tworzenie modelu na podstawie sygnałów wejściowych (danych) i (systematycznie ulepszając) wykorzystują go do tworzenia wniosków, decyzji i wiedzy, zamiast wykonywania liniowych instrukcji – jak w przypadku klasycznych algorytmów i podejścia opisanego we wstępie. Jest to dziedzina z pogranicza informatyki i statystyki oraz ściśle wiąże się z szerszym zagadnieniem sztucznej inteligencji. Najpopularniejsze obszary wykorzystania uczenia maszynowego pojawiają się tam, gdzie standardowe liniowe algorytmy zawodzą – na przykład filtrowanie poczty (spam), rozpoznawanie i przetwarzanie obrazów (w tym OCR) czy silniki wyszukiwania. Uczenie maszynowe w dużym stopniu wiążę się z wyszukiwaniem wzorców, jednak nie można tych terminów używać wymiennie.
Dlaczego jest to takie ważne i dlaczego wyrażenie „machine learning” trafia powoli do świata popkultury i masowej świadomości? Z kilku powodów. Po pierwsze ilość danych rośnie w gigantycznym, wykładniczym tempie. I dalej będzie rosnąć. Jeśli nie chcemy zagrzebać się i zginąć tym informacyjnym szumie, musimy opracować narzędzia, które w pełni automatyczny sposób pozwolą nam na analizę tych danych. Po drugie, eksploracja wiedzy to już nie tylko domena gigantycznych korporacji. Obecnie urządzenia takie jak inteligentne termostaty czy opaski fitness „uczą” się o naszym zachowaniu na podstawie danych wejściowych i generują wyniki, poszukując zależności i regularności w naszych poczynaniach. Podobnie wirtualni asystenci tacy jak Google Now czy Cortana, którzy potrafią na podstawie powtarzalnych danych z GPS poprawnie wywnioskować gdzie jest nasza praca, dom i którą drogą jeździmy do obu tych miejsc. Klasyczny przykład uczenia maszynowego – suche dane wejściowe w postaci koordynatów GPS oraz znaczników czasowych – efekt: określenie na tej podstawie gdzie jest nasz dom, praca i jak wcześnie musimy wyjść z tego pierwszego, żeby nie spóźnić się do drugiego.


Według wielu źródeł, jednym z pierwszych przykładów uczenia maszynowego w praktyce był projekt Arthura Samuela z IBM, który w latach 50-tych tworzył algorytm i aplikację do szkolenia zawodników szachowych. Jednym z najgłośniejszych wydarzeń w tej dziedzinie było powstanie systemu eksperckiego Dendral na Stanford University w roku 1965. System ten powstał w celu zautomatyzowania analizy, grupowania i rozpoznawania molekuł związków chemicznych, nieznanych do tej pory człowiekowi. Wyniki badań otrzymane dzięki temu systemowi były pierwszym w historii bezpośrednim odkryciem dokonanym przez komputer i zostały opublikowane w prasie naukowej.
Gdzie dzisiaj znajdziemy zastosowania algorytmów uczenia maszynowego? Autokorekta w klawiaturze, klawiatury typu swype, wirtualni asystenci, sugestie wyszukiwania, podpowiedzi w pasku przeglądarki, wyznaczanie tras w nawigacji, przewidywanie wyników meczów, algorytmy wyszukiwania, propozycje podobnych filmów i książek, prognozy giełdowe i prognozy pogody. I wiele wiele innych – łatwiej by było wymienić funkcje i aplikacje, które nie wykorzystują uczenia maszynowego.
Nie chciałbym, żeby tekst ten był przegadany i traktował jedynie o bardzo ogólnych aspektach uczenia maszynowego, z których właściwie każdy geek zdaje sobie sprawę. W końcowej części tego podtytułu w telegraficznym skrócie opiszę podstawowe metody wykorzystywane w algorytmach uczenia maszynowego – oczywiście tylko niewielką część ze zbioru wszystkich metod. Osoby które nie lubują się w matematycznych oraz technicznych aspektach i rozważaniach, mogą pominąć tę część bez straty ogólnego przesłania całego tesktu.
Stuczne sieci neuronowe
Enigmatyczna definicja z Wikiepdii podaje: Sieć neuronowa (sztuczna sieć neuronowa) to ogólna nazwa struktur matematycznychi ich programowych lub sprzętowych modeli, realizujących obliczenia lub przetwarzanie sygnałów poprzez rzędy elementów wykonujących pewną podstawową operacjęna swoim wejściu, zwanych neuronami. Aha. Czyli dalej nic nie wiemy. Gdybym miał wytłumaczyć dziecku czym jest sztuczna sieć neuronowa, powiedziałbym, że to skrajnie uproszczony ludzki mózg.
Każdy z nas miał w szkole biologię, więc gdybyśmy chcieli zagłębić się w szczegóły, możemy powiedzieć, że sieć neuronowa jest zbiorem prostych procesorów („neuronów”) połączonych w pewien sposób. Neuron może mieć wiele wejść (synapsy). Ma tylko jedno wyjście. Synapsom można przypisać wagi (mnożniki), których wartość może podlegać zmianom. Topologia (struktura) połączeń oraz wagi stanowią program działania sieci. Sygnały wyjściowe sieci pojawiające się w odpowiedzi na sygnały wejściowe wyznaczają rozwiązanie stawianego sieci zadania. Jeszcze prościej – jest to struktura przetwarzająca dane wejściowe na wyjściowe, a jej topologia (struktura) i wagi neuronów („mnożniki”) decydują o tym JAK dana sieć przetwarza te sygnały, czyli jaki „program” wykonuje. Sieci neuronowe mają zazwyczaj wiele warstw, tak że dane wyjściowe pierwszej warstwy są danymi wejściowymi warstwy drugiej. I tak dalej.
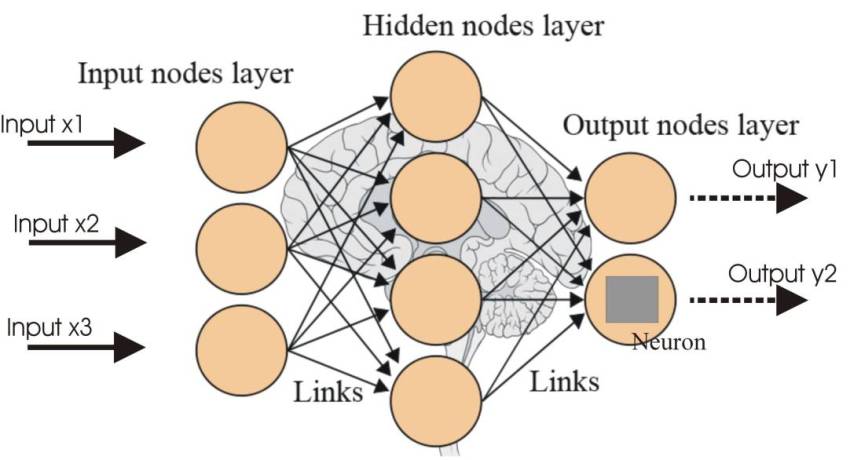

No dobrze, znamy zasadę działania, ale jaki związek ma to z uczeniem maszynowym, skoro to człowiek projektuje tę sieć? Nie wspomniałem jeszcze o procesie uczenia sieci neuronowej. W ogromnym skrócie, jest to iteracyjny (powtarzalny) proces, który polega na dostarczeniu sieci danych wejściowych (zbiór danych uczących), które to dane poprzez dodatkowy neuron uczący modyfikują wagi pozostałych neuronów. Co może być takim zestawem danych uczących? Na przykład zdjęcia (fragmenty zdjęć) numerów domów z Google Maps Street View. Na podstawie takich danych można nauczyć (odpowiednio zaprojektowaną sieć) rozpoznawania nowych numerów – gdy zakończymy proces uczenia sieci i trwale ustalimy wagi i połączenia neuronów.
Uczenie przez wzmanianie
Algorytm uczenia przez wzmacnianie jest, w bardzo dużym uogólnieniu, powtarzalną (rekurencyjną) procedurą zdobywania wiedzy metodą prób i błędów. W terminologii stosowanej w teorii sterowania można powiedzieć, że regulator wchodzi w interakcję z obiektem (środowiskiem czy procesem) sterowania za pomocą trzech sygnałów: stanu, sterowania (akcji) oraz nagrody (lub kosztu sterowania). W każdym kroku algorytmu regulator obserwuje stan obiektu, a następnie wykonuje akcję, przeprowadzającą obiekt do następnego stanu. Jednocześnie regulator otrzymuje sygnał wartościujący (oceniający) wykonaną akcję w postaci nagrody. Po „otrzymaniu” nagrody regulator wykonuje kolejny krok algorytmu.
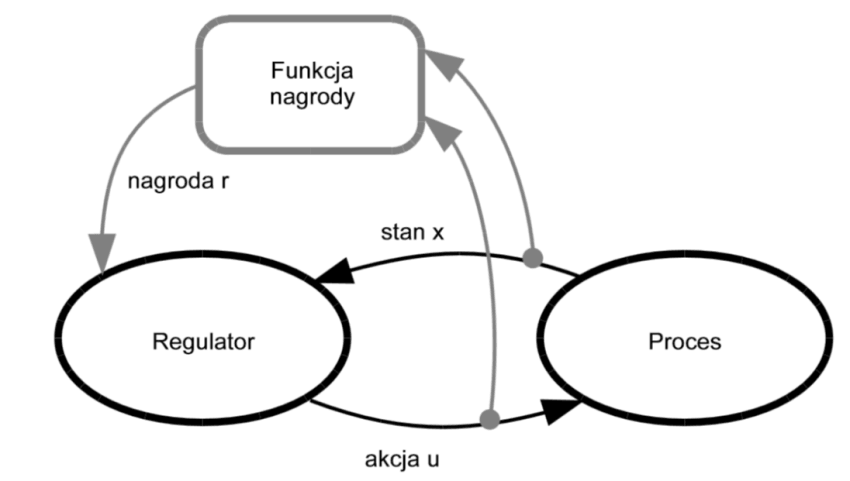

Dużo łatwiej zrozumieć to na przykładzie gry „ciepło-zimno”, która jest klasycznym podejściem uczenia przez wzmacnianie. Stan to nasza aktualna pozycja, sterowanie, to kierunek w którym idziemy w danym kroku. Funkcja nagrody, to „ciepło” lub „zimno”. Jeśli wybieramy dobry kierunek, nasze sterowanie jest wzmacniane („ciepło”, „gorąco”), jeśli natomiast oddalamy się – nagroda jest „ujemna” (kara – „zimno”). Dobre ruchy są nagradzane, złe karane. Na tej podstawie, metodą prób i błędów jesteśmy naprowadzani na właściwy kierunek. Im bliżej jesteśmy celu, tym sygnały nagradzające są mocniejsze (ciepło -> gorąco -> parzy!).
Drzewa decyzyjne
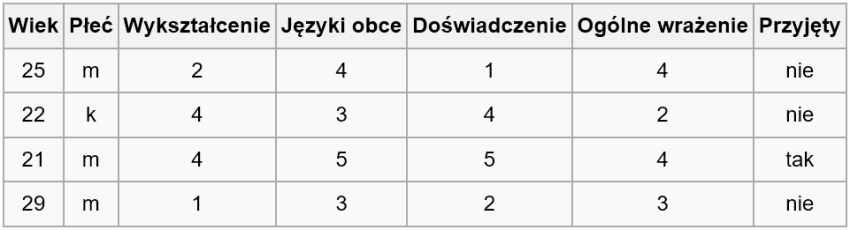
Drzewo decyzyjne to graficzna metoda wspomagania procesu decyzyjnego, a sam algorytm drzew decyzyjnych jest również stosowany w uczeniu maszynowym do pozyskiwania wiedzy na podstawie przykładów. Na razie słusznie nic to nam nie mówi. Jest to narzędzie często wykorzystywane do klasyfikowania i grupowania. Najłatwiej będzie to zrozumieć na (abstrakcyjnym) przykładzie zautomatyzowania systemu zatrudniania w firmie. Danymi uczącymi w tym przypadku będzie zbiór informacji o kilku pracownikach, którzy zostali przyjęci lub odrzuceni po rozmowie kwalifikacyjnej. Na podstawie tych danych, chcielibyśmy stworzyć gotowy algorytm, który pozwoli nam automatycznie odrzucać lub przyjmować pracowników właśnie na podstawie podstawowych danych (np. wiek, płeć, wykształcenie, języki obce, doświadczenie, ogólne wrażenie, czy przyjęty). warto zauważyć, że dane uczące zawierają pozycję „czy przyjęty”, która przyjmuje wartości TAK lub NIE. Pozycja ta będzie wartością poszukiwaną przez algorytm, czyli wynikiem jego działania. Na podstawie pozostałych danych (wiek, płeć, wykształcenie, języki obce, doświadczenie, ogólne wrażenie), algorytm ten wskaże nam propozycję dla pola „czy przyjęty” – TAK lub NIE.

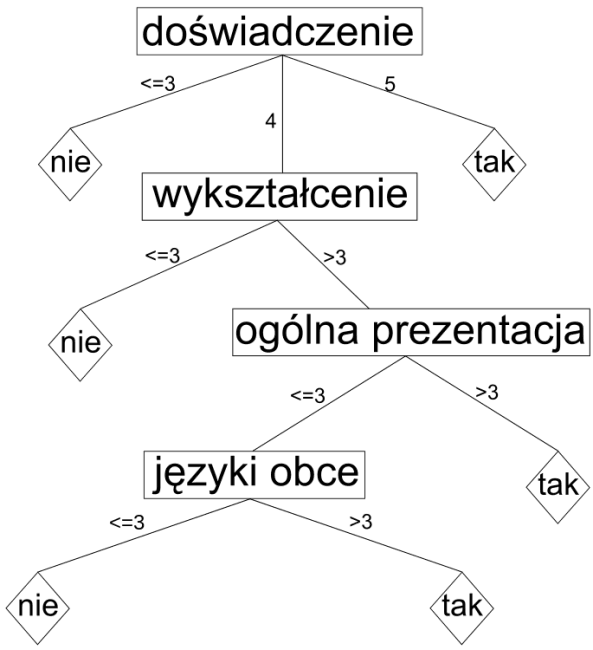
Algorytm ten przyjmuje postać hierarchicznego drzewa decyzyjnego, przedstawionego poniżej. Tworzenie drzewa w automatyczny sposób na podstawie danych uczących to osobne zagadnienie dotykające zaawansowanej matematyki. W skrócie moge powiedzieć, że wykorzystuje ono algorytmy zachłanne i rekurencję, decydując które elementy danych wejściowych, w jakiej kolejności i z jakimi wartościami będą tworzyć docelowe drzewo decyzyjne. Warto zauważyć, że nie wszystkie pozycje z danych wejściowych muszą mieć wpływ na wynik. Pozycja „płeć” okazała się bez znaczenia dla decyzji końcowej, stąd nie ma jej w drzewie decyzyjnym.

Algorytmy genetyczne
Algorytmy genetyczne są to algorytmy poszukiwania rozwiązania pewnych grup problemów, które w rozwiązywaniu zadań stosują zasady ewolucji i dziedziczności. Posługują się wygenerowaną losowo populacją potencjalnych rozwiązań i zawierają proces selekcji, oparty na dopasowaniu osobników oraz pewne operatory genetyczne (np. krzyżowanie, mutacje, reprodukcja). Każde rozwiązanie ocenia się na podstawie pewnej miary jego dopasowania (przystosowania, celu). Nową populację, w kolejnej iteracji, tworzy się przez wybór osobników najlepiej dopasowanych.
Obok sieci neuronowych, to kolejny algorytm bezpośrednio nawiązujący do zjawisk jakie występują w naturze. Znajdują zastosowanie tam, gdzie nie znamy tradycyjnego sposobu rozwiązania problemu, ale znany jest sposób oceny jakości rozwiązania. Przykładem jest np. problem komiwojażera o którym pisałem w tekście o komputerach kwantowych. Sprowadza się do tego, żeby znaleźć najkrótszą drogę łączącą wszystkie miasta, tak by przez każde miasto przejść tylko raz. Ocena „jakości” proponowanej trasy jest bardzo prosta (po prostu szukamy najmniejszej długości), ale znalezienie optymalnej trasy kwalifikuje się do klasy problemów NP-trudnych (po wyjaśnienie również odsyłam do wcześniejszego tekstu). Stosując algorytmy ewolucyjne, rozwiązanie bliskie optymalnemu można znaleźć bardzo szybko, ale nigdy nie będziemy mieć pewności czy jest ono optymalne.
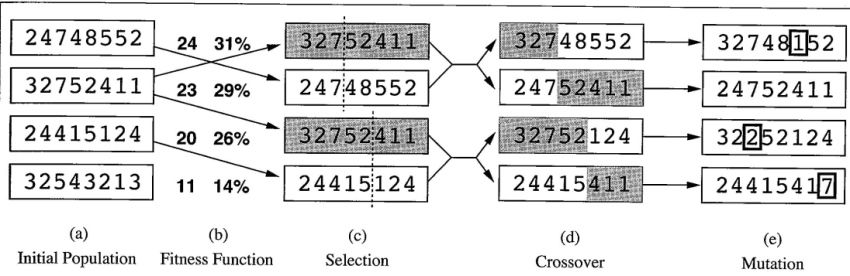

W przypadku problemu komiwojażera z 4 miastami (1 – Warszawa, 2 – Kraków, 3 – Wrocław, 4 – Poznań), długość chromosomu w algorytmie wynosiła by 4 (bo tyle miast musi odwiedzić komiwojażer), liczba możliwych wartości dla pojedynczego elementu to też 4 (bo każde miasto jest numerowane od 1 do 5), a funkcją przystosowania byłaby całkowita długość trasy, kodowanej w następujące sposoby – gdzie każda kolejna pozycja to numer odwiedzanego miasta.
1234 (Warszawa, Kraków, Wrocław, Poznań), 1243 (Warszawa, Kraków, Poznań, Wrocław), 1432 (Warszawa, Poznań, Wrocław, Kraków), itd…
Tak mała skala zadania oczywiście nie ma sensu, ale omówmy krótko podstawowe działania. Na początek wygenerowalibyśmy losowo kilka możliwych kombinacji, np 1234, 1243, 2134, 3214. Pierwszy i drugi na przykład podlegałby mutacji (zamienienie dwóch ostatnich pozycji), dwa pierwsze, dwa środkowe i dwa ostatnie zostałyby skrzyżowane, a ostatni dodatkowo zduplikowany – da to nam 6 nowych ciągów liczbowych. Po tej czynności, policzylibyśmy współczynnik dopasowania dla wszystkich 6, czyli w tym przypadku długość trasy dla każdej z kombinacji. Populacja następna powinna być tak samo liczna jak poprzednia, więc po obliczeniu funkcji dopasowania, dwa najsłabsze osobniki (dwie najdłuższe trasy) byłyby odrzucane. Z 4 osobnikami kolejnej generacji powtórzylibyśmy algorytm mutacji, krzyżowania i replikacji – i tak n-razy (przez n pokoleń), aż uzyskamy coraz to lepszy wynik – o ile dobrze zaprogramowaliśmy algorytm.
Sztuczna inteligencja
Sztuczna inteligencja, czyli ludzka twarz uczenia maszynowego. Jeśli zdecydowaliście się poczytać o podstawowych metodach i algorytmach uczenia maszynowego z poprzedniego podtytułu, możecie czuć pewien niedosyt. Uczenie maszynowe miało być metodą na analizę danych bez wcześniejszego definiowania problemu czy obszarów poszukiwań. Proponowane metody nie do końca realizują to założenie. Nie są one w pełni uniwersalne i wymagają wykonania wielu czynności przygotowawczych. Nie są uniwersalne w takim sensie, że pasują do jedynie części rozwiązywanych klas problemów. Albo są to metody grupowania, albo wspomagania decyzji, albo optymalizacji, albo… Prawdziwie autonomiczna metoda uczenia maszynowego operowałaby na gołych danych i sama „decydowała” jakich metod użyć do ekstrakcji „wiedzy”. Takie uczenie maszynowe uczenia maszynowego.
W tym momencie dochodzimy do znacznie szerszego zagadnienia jakim jest sztuczna inteligencja (artificial intelligence, AI). Na początek znowu posłużymy się definicją z Wikipedii: Sztuczna inteligencja – dziedzina wiedzy obejmująca logikę rozmytą, obliczenia ewolucyjne, sieci neuronowe, sztuczne życie i robotykę. Sztuczna inteligencja to również dział informatyki zajmujący się inteligencją – tworzeniem modeli zachowań inteligentnych oraz programów komputerowych symulujących te zachowania. Można ją też zdefiniować jako dział informatyki zajmujący się rozwiązywaniem problemów, które nie są efektywnie algorytmizowalne.
Definicja tłumaczy bardzo niewiele, ale świetnie wskazuje na rozległość i nieostrość tego terminu. Na potrzeby tego tekstu, przyjmiemy znaczenie, które przypisuje się temu terminowi w śwciecie informatyków i matematyków. Najważniejszymi celami badań nad tą dziedziną jest umożliwienie projektowania maszyn i programów komputerowych zdolnych do realizacji WYBRANYCH funkcji umysłu i zmysłów, które jak na razie nie zostały zalgorytmizowane w prosty, numeryczny sposób. Obszarami zainteresowań są tutaj w szczególności rozumienie języka naturalnego (maszyna która jest w stanie rozmawiać z człowiekiem), podejmowanie decyzji na podstawie niepełnych danych, rozumowanie logiczne, systemy wspomagania decyzji czy dowodzenie twierdzeń. O ile uczenie maszynowe może być elementem AI, to sama sztuczna inteligencja jest czymś więcej. Definicji jest wiele, ale mówiąc obrazowo, przyjmijmy, że sztuczna inteligencja zaczyna się tam, gdzie kończą się standardowe algorytmy numeryczne.
Jak daleko nam do stworzenia sztucznej inteligencji? Samo pytanie jest chyba trudniejsze niż odpowiedź, bo znowu wraca do nas problem definicji. Informatycy śmieją się, że sztuczna inteligencja powstanie „w ciągu najbliższych 10 lat”. Bo takie wyrażenie powtarzane jest od lat 60-tych. Naukowcy i informatycy skutecznie zaprojektowali i stworzyli maszyny, które w nietrywialny sposób potrafią operować na danych wyciągając z nich informacje i wiedzę, która mogła umknąć człowiekowi. Tworzymy również sieci neuronowe, które świetnie symulują ludzkie rozpoznawanie pisma czy mowy. Nawet smartfony mają wbudowane OCR-y czy wirtualnych asystentów, z którymi można „swobodnie” rozmawiać.
![]()

Ważniejszym pytaniem jest jednak to, z czym obecne algorytmy sztucznej inteligencji osbie nie radzą. A zacznijmy od najpopularniejszego problemu, czyli testu Turinga. Test Turinga to system określania zdolności maszyny do posługiwania się językiem naturalnym (mówionym / pisanym). Alan Turing zaproponował ten test w ramach badań nad stworzeniem sztucznej inteligencji. Test wygląda następująco: sędzią jest człowiek, który prowadzi rozmowę w języku naturalnym z pozostałymi stronami. Jeśli sędzia nie jest w stanie wiarygodnie określić, czy któraś ze stron jest maszyną czy człowiekiem, wtedy mówi się, że maszyna przeszła test. Ktoś może powiedzieć, że taki test wcale nie świadczy o żadnej „inteligencji” drugiej strony. Nawet sztucznej. W końcu sprowadza się do generowania wyrażeń w odpowiedzi na wyrażenia rozmówcy i kontekst rozmowy. Zgadza się. Ale nie mówimy tutaj o (samo)świadomości, a o sztucznej inteligencji. Właściwie skąd mamy pewność, że nasze własne odpowiedzi w rozmowach z żywymi ludźmi nie są po prostu zbiorem reguł i dopasowań, które wykonujemy półautomatycznie? Czy maszyna sterowana algorytmami jest mniej inteligentna od nas, skoro potrafi prowadzić z nami rozmowę, a my nie zorientujemy się, ze mamy do czynienia z maszyną?
W roku 2011 program CleverBot, stworzony ponad 20 lat wcześniej przez Rollo Carpentera i od tego czasu ciągle ulepszany (oraz uczący się na podstawie rozmów z użytkownikami), oszukał prawie 60% rozmówców, którzy myśleli, że rozmawiają z człowiekiem. Do „zaliczenia” testu Turinga zabrakło jednak 4%, bo na tych samych zawodach człowieka rozpoznawano prawidłowo w prawie 64% przypadków. Jak widać test jest bardzo niedokładny i tak naprawdę mocno subiektywny. Zależy od obsady sędziów, a sama jego konstrukcja budzi więcej wątpliwości niż przynosi wyjaśnień. W końcu sztuczna inteligencja, to nie tylko porozumiewanie się językiem mówionym. W szczególności znając sobie sprawę, że komputer w żadnym stopniu nie „rozumie” tego co mówimy – jedynie na podstawie ogromnej ilości danych uczących i ciągłego doskonalenia się, właściwie odgaduje jakimi frazami odpowiadać na frazy rozmówcy.
W tym momencie dochodzimy do problemu, który został nazwany chińskim pokojem. To eksperyment myślowy zaproponowany przez Johna Searle, który twierdził, że komputer wykonujący program może mieć „umysł” i „świadomość”. W tym momencie musimy jednak powiedzieć czym jest pojęcie MOCNEJ sztucznej inteligencji. Orędownicy tej idei wierzą, że odpowiednio zakodowany program i komputer nie jest prostą symulacją lub jedynie modelem umysłu, może MYŚLEĆ i mieć stany poznawcze. Podstawą pomysłu jest założenie, że udało się nam skonstruować komputer, który zachowuje się jakby rozumiał język chiński – na chińskie dane wejściowe odpowiada danymi wyjściowymi. Tutaj na myśl przychodzi test Turinga na sztuczną inteligencję. Załóżmy że komputer ów przechodzi ten test, czyli potrafi przekonać chińczyka, że jest żywym człowiekiem mówiącym po chińsku. Propagatorzy mocnej sztucznej inteligencji twierdzą, że w takiej sytuacji możemy uznać, że komputer ROZUMIE język chiński w taki sam sposób jak człowiek. Teraz przyjmijmy, że to my, osoby nie znające chińskiego (Konrad Błaszczak, cicho) siedzimy w środku tego komputera (w chińskim pokoju). Do pomocy mamy jednak książkę z „instrukcją” do języka chińskiego po polsku. Jest w niej pełny opis reguł języka chińskiego, które pomogą nam kreślić znaki będące odpowiedzią na chińskie znaki, które trafią do nas jako dane wejściowe. I tak, nie rozumiejąc języka, a posługując się jedynie zestawem reguł, będziemy „rozmawiać” z Chińczykiem nie znając chińskiego. Searle próbuje pokazać, że będzie to tak naprawdę SŁABA sztuczna inteligencja, czyli jedynie naśladowanie inteligencji, a nie myślenie poznawcze (kognitywne). Zwolenników tego podejścia jest tyle samo co jego krytyków, a argumenty za i przeciw możecie znaleźć w sieci.
Jak zatem zdefiniujemy sztuczną inteligencję? Czy wystarczy, żeby maszyna ZACHOWYWAŁA się jak człowiek (imitacja, płynna rozmowa z Cortaną, sensowne i nieliniowe odpowiedzi komputera), czy może jednak musi BYĆ jak człowiek? W tym miejscu dochodzimy do pojęć takich jak świadomość i samoświadomość. Miejscu, w którym kończy się informatyka i matematyka, a zaczyna filozofia.
(Samo)świadomość
Doskonała sztuczna inteligencja obdarzona byłaby świadomością, a może nawet samoświadomością. Wikipedia definiuje świadomość następująco: podstawowy i fundamentalny stan psychiczny, w którym jednostka zdaje sobie sprawę ze zjawisk wewnętrznych, takich jak własne procesy myślowe, oraz zjawisk zachodzących w środowisku zewnętrznym i jest w stanie reagować na nie. Samoświadomość z kolei to świadomość samego siebie, zdawanie sobie sprawy z doświadczanych aktualnie doznań, emocji, potrzeb, myśli, swoich możliwości, czy ograniczeń, autokoncentracja uwagi. Można zatem powiedzieć, ze samoświadomość jest jednym z elementów świadomości – choć nie każdy świadomy organizm żywy musi być samoświadomy.
Jednym z najpopularniejszych eksperymentów sprawdzających samoświadomość u zwierząt jest test lustra. Pozytywny wynik otrzymujemy wtedy, gdy zwierzę rozpozna swoje odbicie w lustrze (jako JA, a nie jako inną istotę). Oceny rozpoznania dokonuje się, analizując zachowanie zwierzęcia po umieszczeniu na jego ciele (zwykle twarzy) kolorowej kropki, którą może dostrzec wyłącznie w odbiciu lustrzanym. Jeśli zwierzę zacznie próbować ją zdrapać czy zmyć – wskazuje to, że zdaje sobie sprawę, że widzi własne odbicie i zdaje sobie sprawę z własnego istnienia. Obecnie test pozytywnie przechodzą niektóre gatunki naczelnych, słonie, świnie, delfiny i sroki.

Czy maszyny i algorytmy nimi rządzące mogą wykazywać świadomość czy nawet samoświadomość? Problem ten jest na razie nierozstrzygalny na gruncie nauk ścisłych i pozostaje tematem rozważań filozofów. Zwolennicy materialistycznego podejścia do wszechświata i zjawisk postulują, że świadomość jest wytworem ludzkiego mózgu i wynika wprost z jego złożoności. Jeśli udałoby się stworzyć nam superkomputer o złożoności podobnej do złożoności mózgu zwierząt lub ludzi – według nich świadomość „pojawi” się sama jako konsekwencja złożonych systemów (naturalnych lub sztucznych sieci neuronowych). Jest to podejście najbardziej konserwatywne, ale daje również najwięcej nadziei na stworzenie świadomego AI. Pośrednio zakłada one, że człowiek też jest swojego rodzaju komputerem (bardzo złożonym), który realizuje pewien program, zakodowany w strukturze jego mózgu, czyli sieci neuronowych. W tym przypadku, w ogóle można przestać rozróżniać „sztuczną” i „prawdziwą” inteligencję oraz świadomość.
Trochę inaczej, choć od tej samej strony, do problemu podchodzi Dan Dennett, który kwestionuje istnienie obiektywnego zjawiska świadomości i samoświadomości. Według niego wystarczy wyjaśnić działanie mózgu (obszar badań neurokognitywistyki) i będziemy w stanie wyjaśnić wszystkie zachowania człowieka. Nasze wrażenie świadomości ma być jedynie złudzeniem i iluzją, wynikającą ze złożoności naszego mózgu. W tym podejściu, mózg jest jedynie komputerem, który przetwarza dane i wykonuje rozkazy, bez miejsca na wolną wolę czy „realną” samoświadomość. Fizyka i współczesna nauka zajmuje się zjawiskami powszechnymi i obiektywnymi. Świadomość jest cechą wewnętrzną i całkowicie subiektywną i nie wykluczone, że nigdy nie będzie ona mogła zostać opisana sformalizowanym i uporządkowanym językiem nauki. Po więcej informacji odsyłam do jego książek i kilku wykładów na TED.
Istnieją też bardziej radykalne koncepcje. David Chalmers postuluje dwa możliwe scenariusze. W pierwszym z nich, świadomość to immanentna cecha wszechświata. Cecha podstawowa, fundamentalna. Tak jak czas i przestrzeń. To są pewne aksjomaty i podstawy, które przyjmujemy w fizyce i nie określamy ich przyczyn. Byś może nigdy nie odpowiemy na pytanie czym jest czas albo dlaczego przestrzeń istnieje. Podobnie może być ze świadomością. Jeśli przyjmiemy, że jest ona fundamentalnym składnikiem świata w którym żyjemy, odpadnie nam wiele pytań dotyczących tego, skąd się ona wzięła i czego jest skutkiem. „Po prostu jest” – taka odpowiedź nie jest satysfakcjonująca z punktu widzenia poznawczego, ale opisując świat musimy skorzystać z pewnego zamkniętego zbioru aksjomatów. Być może świadomość jest jednym z nich.
Drugi pomysł to powszechność i uniwersalność. Zgodnie z tym pomysłem, jest to kolejna cecha zorganizowanej materii, tak jak masa czy ładunek elektryczny. Według tego podejścia, nawet cząstki elementarne mogą mieć pewne aspekty świadomości, a wraz ze wzrostem złożoności struktur, świadomość ta może przejawiać się w sposób, jaki widzimy na co dzień – w świecie ludzi i zwierząt. Wszystko może mieć świadomość – tak jak cząsteczki mogą mieć masę i ładunek. Tak jak masa neutrino jest zaniedbywalnie mała i nie uwzględnia się jej przy obliczeniach, a masa galaktyki ma realny wpływ na zachowanie materii, tak być może świadomość cząstek elementarnych jest niezauważalna, a świadomość struktur tak złożonych jak ludzie, da się obserwować „gołym okiem”. Mało naukowości w tym podejściu i prawdopodobnie teoria ta nie jest nawet falsyfikowalna, jednak niewątpliwie idea myślącego oceanu czy galaktyki potrafi pobudzić wyobraźnie i znaleźć odzwierciedlenie choćby w książkach Stanisława Lema.


Rosnąca ilość danych, która zalewa nas i wielkie korporacje (z których usług korzystamy) sprawia, że powstają coraz to nowe narzędzia do eksploracji danych. Niektóre z nich ułatwiają nam życie, inne służą do ekstrakcji i analizy naszych zachowań, tak żeby sprzedać nam jakiś produkt czy wyświetlić odpowiednią reklamę. Czasami jest to śmieszne, czasami straszne, a czasami po prostu bardzo pomocne. Mimo tego, że jesteśmy coraz bardziej zaniepokojeni poziomem infiltracji i analizy naszych danych, myślę, że mało kto chciałby wrócić do starego telefonu komórkowego z fizycznymi przyciskami i monochromatycznym ekranem czy komputera bez dostępu do Internetu. A przypominam, że pozbycie się smartfona i podłączenia internetowego, to jeden prosty ruch… na który chyba nie jesteśmy gotowi. Kierunek działań wielkich firm pokazuje, że w przyszłości interakcja z urządzeniami będzie jeszcze prostsza – przy użyciu gestów czy swobodnego języka mówionego. Maszyny będą zachowywały się tak, jakby nas rozumiały (już teraz taka jest właśnie idea stojąca za Google Now czy Cortaną), a my już nigdy nie będziemy chcieli wrócić do „topornych interfejsów obsługiwanych przy pomocy ekranów dotykowych, klawiatur i myszek”.