


Ponad 10 lat temu, po raz pierwszy zacząłem regularnie słyszeć o „cloud computingu”, czyli przetwarzaniu w chmurze. Internet był wtedy czymś niepowszechnym, (po)wolnym i wciąż dość hermetycznym.
Na naprawdę szybkie łącza mogły liczyć jedynie korporacje, duże firmy czy instytucje rządowe, a przeciętny użytkownik od jakiegoś czasu zachwycony korzystał z Neostrady, która była jak objawienie po przesiadce z łącza telefonicznego. Mimo tego, już wtedy „chmura” stała się modnym słowem w świecie IT i nowych technologii. Czytasz gazetę, włączasz TV, otwierasz lodówkę – a tam chmura. Problem w tym, że mało kto wiedział o co w tym tak naprawdę chodzi. Ja również błąkałem się we mgle… a może w chmurze? Zacznijmy od początkowego fragmentu definicji z Wikipedii: Chmura obliczeniowa – model przetwarzania danych oparty na użytkowaniu usług dostarczonych przez usługodawcę. I to jest właśnie jeden z największych problemów związanych z tym terminem. Jego semantyczne znaczenie jest wyjątkowo szerokie i we współczesnym Internecie właściwie ciężko znaleźć coś, co nie jest chmurą lub nie jest w pewien sposób oparte o cloud computing. O jakim computingu/przetwarzaniu mówimy? Znowu z pomocą przychodzi nam Wikipedia: Przetwarzanie danych – przekształcanie treści i postaci danych wejściowych metodą wykonywania systematycznych operacji w celu uzyskania wyników w postaci z góry określonej. Mówimy zatem o przetwarzaniu danych na wszystkich poziomach – od tych nisko do wysokopoziomowych. Mogą być to zarówno zwykłe operacje binarne, jak i operacje na tekście pisanym.


Spróbujmy jednak, na potrzeby tego wpisu, doprecyzować co będziemy nazywać chmurą obliczeniową i jakie są jej najważniejsze cechy. Zacznijmy od zdefiniowania przez zaprzeczenie. Chmurą (oczywiście) nie jest przetwarzanie danych lokalnie – używając naszego lokalnego, dysku, procesora i pamięci RAM. Czy cloud computing jest więc zwyczajnym wykorzystaniem zasobów zdalnych (przez sieć LAN czy Internet) do przetwarzania informacji? Można powiedzieć, że jest to warunek konieczny, ale niewystarczający. Kolejnym koniecznym warunkiem jest dostarczenie użytkownikowi usługi, a nie produktu. Jak to rozumieć? Posłużmy się dwoma przykładami. Pierwszy z nich to sieć elektryczna i medium, jakim jest prąd. Użytkownik płaci za usługę – dostęp (i wykorzystanie) prądu z sieci elektrycznej. Nie obchodzi go infrastruktura, elektrownia, obciążenie linii średniego i wysokiego napięcia, itd… Interesuje go usługa – napięcie w gniazdku, prąd zasilający domowe urządzenia. Przeciwnym podejściem byłoby wykorzystanie domowego generatora prądu i zasilanie gospodarstwa we własnym zakresie – a to wiązałoby się z kupnem tego generatora, dostarczaniem paliwa do niego, regularnym serwisowaniem czy wymianą go po kilku latach. Kupując generator, kupujemy produkt. Podpisując umowę z dostawcą energii elektrycznej – kupujemy usługę dostarczaną nam przez sieć energetyczną. Jak przenieść to na realia przetwarzania w chmurze? Pomyślmy o składowaniu informacji. Standardowe „niechmurowe” podejście kup produkt, to nabycie lokalnego dysku twardego lub fizycznego serwera u zewnętrznego dostawcy. Podejście cloud computing, czyli kup usługę, to zapłacenie za wybraną przestrzeń dyskową i dostęp do niej przez sieć (np. Internet). Klient płaci za usługę, a nie fizyczny dysk, więc nie musi martwić się gdzie dokładnie składowane są jego dane. To dostawca usługi ma zapewnić dostępność danych, stabilność łączy, szybkość transmisji czy bezpieczeństwo. Podsumowując – chmura to rozporoszone zasoby obliczeniowe i dyskowe oraz dostęp do nich na zasadzie korzystania z usług za pomocą łącza danych. Zasada działania polega więc na przeniesieniu obowiązku świadczenia usług na serwer i umożliwienie stałego dostępu poprzez komputery klienckie. Dzięki temu ich bezpieczeństwo nie zależy od tego, co stanie się z lokalnym komputerem, a szybkość usług wynika z mocy obliczeniowej serwera.


Historia i możliwości
Skoro zawęziliśmy już definicję przetwarzania w chmurze, to warto wspomnieć o historii i początkach tego podejścia. Pochodzenie samego terminu nie jest do końca jasne, ale w świecie nauki chmurą zwykło się nazywać duże zbiory obiektów, które widziane z daleka zaczynają tworzyć całość i tak się właśnie je opisuje, bez zagłębiania się w szczegóły i elementy składowe. To określenie bardzo dobrze oddaje podejście do oferowania usług w chmurze – gdzie infrastruktura, serwis czy administracja nie jest w obrębie zainteresowań odbiorcy końcowego. Sam termin pierwszy raz pojawia się w wewnętrznym dokumencie, który trafił do pracowników firmy Compaq w roku 1996. Na trwałe do świadomości opinii publicznej trafił jednak dopiero wtedy, gdy Jeff Bezos ze swoim Amazon.com wprowadził na rynek usługę Elastic Compute Cloud. Podstawową ideą stojącą za chmurą obliczeniową można dostrzec jednak już w rozwiązaniach z lat 50-tych, kiedy zasoby dużych komputerów typu mainframe były udostępniane lokalnym komputerom-klientom o prawie zerowej mocy obliczeniowej. Na kolejny duży przełom trzeba było czekać do lat 90-tych, kiedy to firmy telekomunikacyjne zaczęły oferować wirtualne sieci prywatne (VPN), pozwalające na korzystanie z porównywalnej jakości usług, co za pomocą łącz point-to-point, zapewniając jednak zauważalnie niższą cenę. Po roku 2000 wiele dużych koncernów branży IT zainwestowało w rozwój własnej chmury, a więcej o obecnej sytuacji na rynku napiszę w dalszej części tego wpisu.
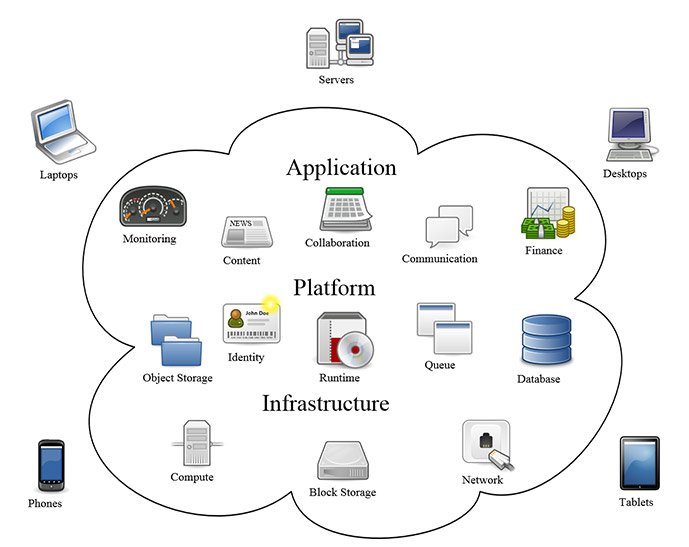
Jak ustaliliśmy wcześniej, pojęcie chmury jest bardzo szerokie i niejednoznaczne – w rozległym znaczeniu, przetwarzaniem w chmurze jest wszystko, co jest przetwarzane poza lokalną zaporą sieciową. Na potrzeby tego wpisu operujemy jednak węższym zakresem znaczeniowym i utożsamiamy chmurę ze zdalnymi usługami dostępnymi z komputerów i urządzeń klienckich. No właśnie – dostępnymi usługami. Jakimi konkretnie? Przyjrzyjmy się trzem najważniejszym. Zacznijmy od najniższej warstwy całego systemu idąc po kolei w górę:
IaaS (Infrastructure as a Service) – czyli infrastruktura jako usługa. W ramach tego rozwiązania klientowi dostarczana jest infrastruktura informatyczna, czyli sprzęt, oprogramowanie i serwis. Użytkownik płaci za konkretną ilość zasobów – przestrzeń dyskową czy określony zasób pamięci i mocy obliczeniowej. Nie oznacza to jednak, że sprzęt został fizycznie przydzielony klientowi. Hardware może być wymieniany, dublowany i rozproszony, a odbiorcę końcowego interesują jedynie dostępne zasoby. W praktyce, wykorzystuje się tu często izolowane maszyny wirtualne z obrazem systemu operacyjnego gotowego do zainstalowania.
PaaS (Platform as a Service) – czyli platforma jako usługa. Jak sama nazwa wskazuje, dostawca zapewnia nam dostęp do całej platformy obliczeniowej – zwykle jest to zainstalowany już system operacyjny z środowiskiem uruchomieniowym, bazą danych i web serwerem. Twórcy aplikacji i rozwiązań internetowych mogą tworzyć i uruchamiać swoje oprogramowanie „w chmurze” bez konieczności inwestowania i utrzymywania zarówno sprzętowych, jak i programowych warstw infrastruktury sieciowej. Przykładami dostawców takich rozwiązań są choćby Microsoft Azure, Amazon Web Services czy Google App Engine.
SaaS (Software as a Service) – czyli oprogramowanie jako usługa. To temat, który najbardziej powinien zainteresować pojedynczych odbiorców usług i fanów urządzeń przenośnych. Najprościej rzecz ujmując, jest to umożliwienie dostępu do aplikacji, które cały swój „silnik” mają w chmurze. Przykładem może być Google Docs czy Office Online, do których dostęp uzyskujemy przez przeglądarkę. W przypadku płatnych usług, nie kupujemy produktu jako takiego, a jedynie dostęp do niego na określony czas – najczęściej na miesiąc lub rok.
Ok, ale po co to wszystko? Dlaczego nie możemy korzystać z lokalnych zasobów? Dlaczego nie możemy kupować oprogramowania na własność? W skrócie – dla wygody i zmniejszenia ponoszonych kosztów. Ale po kolei. Chmura to skalowalność – potrzebujemy więcej zasobów w postaci przestrzeni dyskowej, mocy obliczeniowej czy transferu? Dwa kliknięcia i załatwione – bez konieczności zmagania się z restrukturyzacją istniejącej infrastruktury. Pomocne jest też API oparte najczęściej na standardzie Representational State Transfer (REST), które pozwala maszynom zewnętrznym na interakcję z chmurą w podobnym zakresie, co żywy użytkownik. Dzięki dużej, złożonej infrastrukturze spadają też ceny usług i eliminowana jest konieczność ponoszenia nakładów finansowych na utrzymywanie własnej infrastruktury. Zaletą jest też brak zależności od sprzętu. Komputer czy tablet są tylko klientami, interfejsem dla usług, które „gnieżdżą się” na serwerach w chmurze. Uszkodzenie lokalnego sprzętu nie skutkuje utratą danych czy brakiem dostępu do usług. Zaletą jest też łatwiejsze monitorowanie wydajności i optymalizacji naszych aplikacji czy infrastruktury wirtualnej. Co jeszcze? Wielodostęp do wspólnych zasobów (współpraca), niezawodność czy bezpieczeństwo – choć to ostanie, to sprawa sporna i zależna od wielu czynników.
Chmura to jednak nie tylko plusy. Wad i ograniczeń jest równie wiele, ale skupimy się na kilku najważniejszych.
Ograniczenia i związek z tabletami
Po pierwsze – stały dostęp do Internetu, najlepiej za pomocą szybkiego i stabilnego łącza. O ile duże firmy mogą sobie na to pozwolić, konsument indywidualny nie zawsze jest w stanie korzystać z tej możliwości na wystarczająco wysokim poziomie. Brak połączenia = brak dostępu do usług zapewnianych przez chmurę. Ale nawet samo połączenie nie wystarczy. Jeśli nie będzie stabilne i szybkie, jakość korzystania z serwisów będzie niska i zniechęcająca dla przeciętnego użytkownika. Drugą kwestią jest bezpieczeństwo. Oczywiście korzystając z zaufanych usługodawców, możemy liczyć na wysoki poziom zabezpieczeń sprzętowych i systemowych, ale mimo tego, nadal przechowujemy własne, czasami newralgiczne dane, na obcych serwerach, całkowicie oddając kontrolę nad nimi. Już nieraz zdarzały się duże wpadki, nawet poważnym graczom, takim jak Dropbox czy Google Drive. Ale bezpieczeństwo danych, to nie tylko ataki z zewnątrz. Korzystając z darmowych dysków sieciowych powinniśmy dokładnie przeczytać regulamin świadczenia usługi i przekonać się na ile pozwalamy świadczeniodawcy. Czy ma on prawo do dowolnego dysponowania naszymi plikami? Czy przechodzą one na jego własność? Nie czuję się na siłach analizować tego od strony prawnej, jednak zachęcam wszystkich do zapoznania się z regulaminami i przemyślenia jakie pliki chcemy trzymać w chmurze oraz czy automatyczny upload zdjęć na Google+, OneDrive czy Dropbox będzie rozsądny.

Kolejną ważną usługą może być granie w chmurze. Może być, bo jeszcze nie jest. Nie jest, bo nadal problematyczna jest szybkość łącza i opóźnienia z tym związane oraz moc obliczeniowa serwerów. Sama usługa polega na udostępnieniu gry przez łącze internetowe w formie strumienia danych, gdzie sam silnik gry znajduje się na serwerach operatora platformy czy samego wydawcy gry. Gracz wchodzi w interakcję z grą przesyłając na serwer jedynie dane wejściowe (sterowanie), a zwrotnie otrzymuje strumień wideo gotowy do odtworzenia. Dzięki temu nie potrzeba złożonych obliczeń lokalnych i obciążania CPU i GPU. W teorii brzmi świetnie, w praktyce – na razie jeszcze technologia nie dorosła do tego rozwiązania – głównie ze względu na opóźnienia na łączach i problem ze skalowalnością klastrów serwerów w chmurze. Zespoły Xboxa, PlayStation czy Nvidii pracują już nad takimi rozwiązaniami próbując eliminować negatywne zjawiska i niewykluczone, że już niedługo uzyskamy dostęp do usług, które będą wystarczająco dobre zarówno w teorii, jak i praktyce.
Od grania w chmurze przechodzimy płynnie do podobnej, choć dużo szerszej opcji – system operacyjny jako usługa. Jakby to miało wyglądać? Tak jak w przypadku gier – wszystkie obliczenia, zarządzanie pamięcią i przestrzeń dyskowa byłyby zapewnione przez usługodawcę, a użytkownik otrzymywały jedynie obraz do wyrenderowania – na podobnej zasadzie jak działa zdalny pulpit czy popularny TeamViewer. Użytkownik wykupowałby usługę jaką jest dostęp do systemu operacyjnego i określonych zasobów (mocy procesora, pamięci RAM czy przestrzeni dyskowej). Po zalogowaniu się zobaczyłby ekran startowy/pulpit, gdzie mógłby instalować aplikacje, programy, zapisywać pliki, korzystać z mocy obliczeniowej wewnątrz uruchomionych programów itd… Jednym słowem nie różniłoby się to niczym od normalnego korzystania z urządzenia mobilnego czy laptopa. Problem zacząłby się jednak wtedy, gdybyśmy utracili połączenie z Internetem. Brak połączenia równałby się całkowitemu brakowi dostępu do usługi. Stąd najprawdopodobniej wprowadzane będą rozwiązania hybrydowe. Na naszym tablecie dalej będziemy mieli mocny procesor, pamięć wewnętrzną i RAM do lokalnych operacji offline na wypadek braku łączności. Na razie jest to jedyne sensowne wyjście, ale nie taka jest idea stojąca za systemem operacyjnym w chmurze. W świecie idealnym, z powszechnym, szybkim i stabilnym Internetem, nosilibyśmy przy sobie jedynie leciutkie i cieniutkie „ekrany” będące interfejsem fizycznym dla środowiska operacyjnego opartego na cloud computingu. Urządzenia takie nie musiałyby mieć dużej pamięci wewnętrznej i zadowoliły się bardzo podstawowym procesorem oraz modemem do łączności. A to oznaczałoby bardzo niską cenę. W dodatku, takich „tabletów” moglibyśmy mieć kilka – o różnych wielkościach ekranu, dających jednak dostęp do tych samych zasobów. Problem kradzieży czy uszkodzenia zszedłby zdecydowanie na drugi plan. Podsumowując – ideą jest przeniesienie wszelkich zaawansowanych obliczeń i magazynowania danych do chmury oraz traktowanie lokalnych urządzeń jedynie jako ekranowe interfejsy do usługi, jaką jest dostęp do systemu operacyjnego.
Jednymi z głównych dostawców przetwarzania w chmurze są Microsoft, Amazon i Google z odpowiednio Microsoft Azure, Amazon Web Services i Google Cloud Platform. Oferta tych firm być może nie zainteresuje pojedynczego użytkownika domowego, ale w tak szybko rozwijającym się świecie technologii mobilnych i rozproszonych warto zdawać sobie sprawę, które koncerny stawiają na własną infrastrukturę chmury obliczeniowej. Dość szybko można zauważyć, że wśród tych firm nie ma Apple. To prawda, firma ta nie oferuje rozwiązań cloud computing dla firm, a własną infrastrukturę opiera często o rozwiązania konkurencji, choćby właśnie Azure od Microsoftu do oferowania usług związanych z iCloud. To ważne, bo od tego będzie zależeć czy nasz ekosystem nadąży za duchem czasu i w przyszłości zaoferuje nam usługi, o których pisałem wcześniej – choćby granie w chmurze czy dostęp do zdalnego systemu operacyjnego z wszystkimi jego dobrodziejstwami.


Podsumowanie
Zdefiniowaliśmy czym jest chmura obliczeniowa jako usługa, powiedzieliśmy o korzyściach, możliwościach i zagrożeniach z tym związanych. Co dalej? Pozostaje nam czekać na rozwój sytuacji i już wkrótce będziemy musieli decydować jak głęboko chcemy rezygnować z naszego lokalnego przetwarzania danych, na korzyść cloud computingu. Temat przechowywania wszystkich swoich danych na serwerach dużych firm jest bardzo kontrowersyjny i z pewnością dalej będzie budził skrajne emocje. Na szczęście wszystko wskazuje na to, że jeszcze długi czas będziemy mieli wybór i to my zdecydujemy, co będzie się działo z naszymi plikami, aplikacjami czy całymi systemami operacyjnymi. Mnie dużo bardziej ciekawi warstwa technologiczna i potencjalne możliwości, a dyskusje o prawach własności, prywatności i bezpieczeństwie pozostawiam osobom, które są do tego bardziej wykwalifikowane.