
Jak to się dzieje, że w swoim urządzeniu klikacie „Wyślij”, a sekundę później ta wiadomość dociera do odbiorcy po przeciwnej stronie globu? Jaka magia stoi za możliwością przesłania ciągu zer i jedynek w taki sposób, że możemy oglądać transmisję w jakości 4K nadawaną na żywo? Jeśli nie wiecie, w jaki sposób dane podróżują poprzez sieć, to serdecznie zapraszam, bo dzisiaj zajmiemy się właśnie tym tematem.
Czym w zasadzie jest Internet?
Internet zdefiniować można jako bardzo rozległą sieć komputerową, przy czym należy zaznaczyć, że sieć komputerowa tworzona jest już przez dwa połączone ze sobą urządzenia. Czy połączenie zrealizowane jest za pomocą kabli telefonicznych, czy za pomocą światłowodów, czy za pomocą fali radiowych lub łączności satelitarnej – nie ma to żadnego znaczenia. Konieczna jest jedynie możliwość wzajemnej komunikacji pomiędzy urządzeniami. W tej dziedzinie rewolucja rozpoczęła się w latach 60. ubiegłego wieku, gdy na potrzeby amerykańskiej armii stworzono coś, co nazwane zostało protokołem IP. Internet Protocol, bo tak brzmi jego nazwa, jest ściśle określonym standardem wymiany informacji pomiędzy urządzeniami, niezależnie od ich typu oraz środka łączności. Jego zadanie polega między innymi na dzieleniu przesyłanych informacji na odpowiedniej wielkości bloki, czyli pakiety.
IP nie jest jednak zbyt samodzielny, ponieważ nie gwarantuje spójności przesłanych informacji. Inaczej mówiąc, część pakietów może nie dotrzeć, część może zostać zdublowana, a część może dotrzeć do odbiorcy w kolejności innej, niż kolejność nadania. Mimo to protokół IP jest powszechnie wykorzystywany praktycznie wszędzie, natomiast odbywa się to we współpracy z protokołem TCP. Transmission Control Protocol odpowiada za sterowanie transmisją i dba między innymi o to, by dane dotarły od nadawcy do odbiorcy w jednym kawałku. Być może spotkaliście się kiedyś z określeniem TCP/IP; teraz już wiecie, że to model łączący oba protokoły i stanowiący fundament tego, w jaki sposób działa Internet. Nie muszę oczywiście dodawać, że TCP/IP również został stworzony na potrzeby wojska.

Słowo klucz – decentralizacja
Potrzeba jest matką wynalazków – model TCP/IP nie powstałby, gdyby amerykańska armia nie potrzebowała sieci odpornej na ataki. Precyzując – przy projektowaniu protokołu IP starano się uchronić sieć ARPANET przed atakami jądrowymi. Jak zapewne domyślacie się po tytule tego nagłówka, zdecydowano się na decentralizację oraz na rezygnację ze stałej struktury sieci. Z prostego powodu – gdyby cała sieć była sterowana z jednego, głównego serwera, jeden precyzyjny atak mógłby doprowadzić do wyłączenia dosłownie całego Internetu. Tymczasem decentralizacja pozwala na funkcjonowanie poszczególnych segmentów sieci niezależnie od siebie. Nie da się ukryć, że gdyby nie Zimna Wojna, to Internet, jaki znamy dzisiaj, mógłby powstać znacznie później; istnieje nawet możliwość, że jego struktura wyglądałaby zupełnie inaczej.
No dobrze, ale skoro calutki Internet jest zlepkiem pomniejszych sieci, to w jaki sposób wiadomość nadana na moim komputerze jest w stanie dotrzeć na drugą stronę kuli ziemskiej? Aby to zrozumieć, dobrze jest poznać, w jaki sposób informacje w ogóle podróżują przez sieć. Zerknijcie na poniższy zrzut ekranu – to jest droga, jaką musi przebyć żądanie, by strona Tabletowo mogła wyświetlić się w mojej przeglądarce.
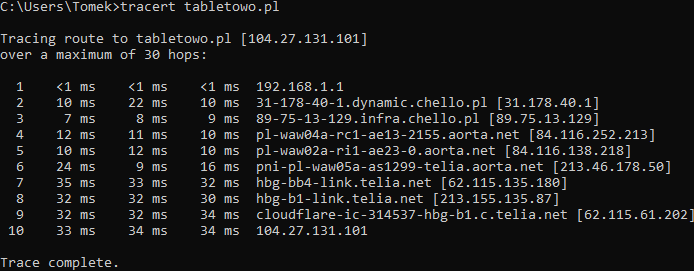
Pierwszy adres to adres lokalny mojego domowego routera. Każdy następny to kolejny przystanek, choć bardziej pasuje tutaj określenie „kontrola graniczna” – routery zajmują się bowiem routingiem (a to niespodzianka), czyli przekazują ruch od nadawcy do odbiorcy. Trasa wybierana jest optymalnie – routery starają się przesłać dane jak najkrótszą trasą, natomiast jest ona ustalana dynamicznie, a pod uwagę brane jest na przykład aktualne natężenie ruchu na danej trasie. Innymi słowy pakiet może polecieć okrężną drogą, przy czym protokół TCP dba o to, by dane dotarły w całości.
Wiadomość nie może zostać wysłana bez celu
Tylko co to właściwie znaczy? Kiedy wysyłacie do kogoś list (tak się kiedyś rozmawiało na odległość, serio!), na kopercie musicie napisać dokładny adres nadawcy – kraj, miasto, ulicę, numer domu/mieszkania i kod pocztowy. W Internecie te wszystkie dane obrazowane są przez adres IP, który musi jednoznacznie identyfikować odbiorcę. Za adresowanie odpowiada również protokół IP – obecnie wykorzystywana są wersje IPv4 oraz IPv6. Ta pierwsza oferuje adres o rozmiarze czterech bajtów, zaś druga rozszerzyła ten zakres do aż szesnastu bajtów. Tylko co to właściwie znaczy? 4 bajty oznaczają 32 bity, a to odpowiada dokładnie 4 294 967 296 unikalnym adresom. Sposób obliczania jest bardzo prosty – należy podnieść dwójkę do potęgi równej ilości bitów.
4 miliardy to całkiem spora liczba adresów, prawda? Otóż nie do końca. Ponad dwadzieścia lat temu, kiedy Internet dopiero raczkował, odpowiednie instytucje starały się jakoś zarządzać adresami; przykładowo firmom były one przydzielane w większych pakietach. Sam IBM dostał do dyspozycji 16 milionów adresów. Ktoś mądry zauważył jednak, że w ten sposób przed nowym milenium pula adresów zostanie wyczerpana, a to oznaczałoby kompletną katastrofę i brak możliwości rozbudowy sieci. Następstwem było stworzenie właśnie szóstej wersji protokołu IP (IPv6) operującej na 18 bajtach – daje to 128 bitów, co jest równe dokładnie 340 282 366 920 938 463 463 374 607 431 768 211 456 unikalnym adresom. To już naprawdę konkretna liczba.
IPv4 nie został jednak wycofany i nadal jest powszechnie używany równolegle z IPv6. Powodów jest kilka – przede wszystkim zostały wdrożone jeszcze inne technologie, mające zapewnić większą elastyczność sieci. W połączeniu z nimi okazuje się, że IPv4 w zupełności wystarcza do większości sieci, a ponieważ operuje on na mniejszej ilości bitów, jego obsługa jest przez to po prostu szybsza.

Podaj mi swój adres IP, a powiem ci… w sumie to nic ci nie powiem
Pierwszą z technologii usprawniających adresowanie w sieci były tak zwane dynamiczne adresy IP. Idea jest bardzo prosta – adres danego urządzenia jest mu przydzielany w momencie podłączenia się do sieci. Po skończonym użytkowaniu adres jest odbierany i może być przydzielony do innego urządzenia. Zobrazujmy to na przykładzie – w naszej sieci możliwe jest jednoczesne podłączenie stu osób, natomiast użytkowników jest, powiedzmy, dwa razy tyle. Jednakże ktoś mądrze zauważył, że te dwieście osób nie korzysta z sieci jednocześnie, a więc nie ma potrzeby sztywnego przydzielania adresów.
W ten sposób routery działają po dziś dzień i między innymi dlatego nie ma konieczności żmudnego konfigurowania urządzeń po zakupie takowego routera. Ustawiacie sobie nazwę sieci, hasło i to tak naprawdę wszystko – protokół DHCP (Dynamic Host Configuration Protocol) dba o to, by każde podłączone urządzenie dostało unikalny zestaw parametrów. Gdyby go nie było, to każda osoba odwiedzająca Wasze mieszkanie musiałaby prosić nie tylko o podanie hasła do Wi-Fi, ale także o skonfigurowanie jej własnego adresu na domowym routerze.
To jednak nie wszystko. Dynamiczne adresowanie niewątpliwie pozwala zaoszczędzić nieco adresów, natomiast to wciąż nie wystarcza. Stworzono więc NAT, czyli Network Address Translation. Zastosuję tutaj proste porównanie – wyobraźcie sobie stół ze smakołykami (serwer), dwie grupy osób (dwie sieci) oraz jednego kelnera (router obsługujący NAT). Jedna z osób mówi „chcę ciastko”, więc kelner idzie do stołu, bierze ciastko i daje je tej konkretnej osobie. Gdy dana osoba chce porozmawiać z kimś z drugiej grupy, wysyła kelnera, by ten w jej imieniu przekazał konkretnej osobie z drugiej grupy wiadomość wraz z informacją, od kogo owa wiadomość pochodzi. Czy osoby w dwóch grupach muszą wiedzieć, gdzie dokładnie siedzi ich rozmówca? Nie muszą, ponieważ kelner pośredniczy w komunikacji i to na jego głowie spoczywa konieczność pamiętania o tożsamości nadawcy oraz odbiorcy.
I to jest tak naprawdę esencja struktury Internetu. Rolę owego kelnera przekazującego dane pełnią właśnie routery. Jeśli Ty oraz Twój sąsiad posiadacie własne routery, to lokalne adresy Waszych urządzeń pokrywają się. Same routery są jednak identyfikowane jednoznacznie, ale tylko w obrębie sieci dostawcy Internetu – u innego dostawcy prawdopodobnie istnieją routery, które mają te same adresy. Wyżej znajduje się identyfikowanie konkretnych dostawców, jeszcze wyżej identyfikowanie konkretnych organizacji, konkretnych państw, i tak dalej, i tak dalej. Wykonajmy teraz nieco uproszczone obliczenie – skoro na 32 bitach możemy zapisać 4 294 967 296 adresów, to znaczy, że do jednego routera możemy podłączyć właśnie tyle kolejnych routerów, z których każdy obsługuje kolejne 4 294 967 296 adresów; łącznie w takiej sieci może znaleźć się więc 18 446 744 073 709 551 616 urządzeń. Oczywiście obliczenia są uproszczone – w grę wchodzą jeszcze takie rzeczy, jak adresy prywatne, adresy rozgłoszeniowe i bardzo istotne maski podsieci, ale nie będę Was już zamęczał typowo informatycznymi rzeczami.
Jeszcze jedna, drobna sprawa – dynamiczne adresy IP oraz NAT sprawiają, że utrudnione jest namierzenie konkretnego użytkownika po adresie IP; w jednym momencie ma adres taki, a za godzinę, na przykład po zrestartowaniu routera, zupełnie inny. Nie bójcie się jednak, dane nie znikają – służby są w stanie prześledzić dokładną trasę na podstawie innych śladów, ot, choćby billingów prowadzonych przez dostawców. Jest to jednak pewna forma anonimowości przynajmniej względem innych normalnych użytkowników, co niewątpliwie jest ogromną zaletą.

Misternie upleciona i niezwykle elastyczna struktura
Jeśli wcześniej nie mieliście pojęcia o tym, jak działa Internet, to mam nadzieję, że pomogłem coś wyjaśnić. Wspomniane protokoły i rozwiązania nie są oczywiście wszystkim – wykorzystywany jest na przykład protokół DNS (Domain Name System), dzięki któremu przy łączeniu się z Tabletowo wpisujecie w przeglądarce tabletowo.pl, a nie 104.27.131.101. Nie próbujcie jednak wchodzić pod ten adres, ponieważ Cloudflare nie zezwala na dostęp do strony bezpośrednio po adresie. Ot, takie zabezpieczenie. Oprócz tego mamy również „konkurenta” protokołu TCP, czyli UDP, który oferuje znacznie szybsze przesyłanie danych, natomiast nie gwarantuje ich spójności i tego, że w ogóle dotrą na miejsce. Z tego też powodu przeznaczony jest do nieco innych zastosowań, bo w tej wielkiej strukturze Internetu po prostu by się nie sprawdził.
Przedstawione powyżej informacje są oczywiście uproszczone na tyle, na ile to konieczne. Jeśli ktoś będzie zainteresowany odkrywaniem niuansów sieci, to z pewnością dotrze do źródeł wyjaśniających wszystko bardzo szczegółowo. Jest to jednak wiedza mocno specjalistyczna, natomiast przeciętnemu użytkownikowi sieci ten artykuł powinien wyjaśnić naprawdę sporo rzeczy. To, co nazywamy Internetem, to podsieć podsieci podsieci podsieci podsieci jakiejś sieci, będącej podsiecią podsieci… no, myślę, że rozumiecie, o co chodzi. Do zobaczenia!
źródło: brain.fuw.edu.pl